Summary
Pendahuluan
Linked List adalah struktur data yang terdiri dari urutan rekaman data sehingga setiap catatan ada bidang yang berisi referensi ke catatan berikutnya dalam urutan. Linked list digunakan dalam banyak algoritma untuk memecahkan masalah real-time, ketika jumlah elemen yang akan disimpan tidak dapat diprediksi dan juga selama akses berurutan elemen.
Jenis-Jenis Linked List
1. Single Linked List
Linked List merupakan koleksi linear dari data, yang disebut sebagai nodes, dimana setiap node akan menunjuk pada node lain melalui sebuah pointer. Ini adalah struktur data yang terdiri dari sekelompok node yang bersama-sama mewakili suatu urutan. Di bawah bentuk paling sederhana, setiap simpul terdiri dari data dan referensi (dengan kata lain, tautan) ke simpul berikutnya dalam urutan. Struktur ini memungkinkan penyisipan (Insertion) atau penghapusan (Deletion) elemen yang efisien dari posisi apa pun dalam urutan selama iterasi. Varian yang lebih kompleks menambahkan tautan tambahan, yang memungkinkan penyisipan atau penghapusan yang efisien dari referensi elemen sewenang-wenang.

2. Double Linked List
Double linked list adalah jenis linked list di mana setiap node selain menyimpan datanya memiliki dua tautan. Tautan pertama menunjuk ke simpul sebelumnya dalam daftar dan tautan kedua menunjuk ke simpul berikutnya dalam daftar. Node pertama dari daftar memiliki tautan sebelumnya yang menunjuk ke NULL sama dengan simpul terakhir dari daftar memiliki simpul berikutnya yang menunjuk ke NULL.

3. Circular Linked List
- Circular Single Linked List
Circular single linked list adalah jenis struktur data yang terdiri dari node yang dibuat menggunakan struktur referensial sendiri. Masing-masing node berisi dua bagian, yaitu data dan referensi ke daftar simpul berikutnya.
Hanya referensi ke simpul daftar pertama yang diperlukan untuk mengakses seluruh linked list. Ini dikenal sebagai head. Node terakhir dalam daftar menunjuk ke head atau node pertama dari daftar. Itulah alasan mengapa ini dikenal sebagai circular linked list.

Struktur Node membentuk simpul daftar tertaut. Ini berisi data dan pointer ke node daftar tertaut berikutnya. Ini diberikan dengan code sebagai berikut.
struct Node {
int data;
struct Node *next;
};
Source :
https://www.tutorialspoint.com/cplusplus-program-to-implement-circular-singly-linked-list
- Circular Double Linked List
Dalam Circular Doubly Linked List, dua elemen berurutan dihubungkan atau dihubungkan oleh pointer sebelumnya dan selanjutnya dan titik terakhir menunjuk ke node pertama dengan pointer berikutnya dan node pertama juga menunjuk ke node terakhir oleh pointer sebelumnya.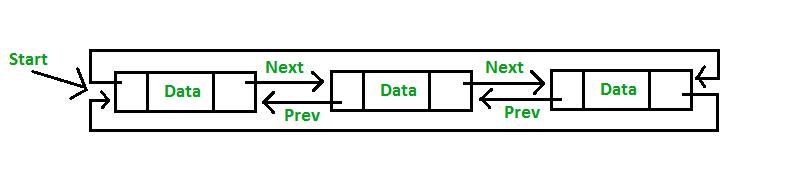
Insertion & Deletion
Insertion berarti memasukan data dan biasa disebut dalam fungsi "push()". Sedangkan Deletion berarti menghapus data dan biasa disebut dalam fungsi "pop()".
Single Linked List
Dalam Single Linked List yang harus kita ingat konsepnya adalah "Head - Tail" dengan Tail yang menuju ke NULL . Lalu terdapat variabel "Current" yaitu data yang ingin kita sisipkan / tambah.
Dalam Linked List ini terdapat berbagai macam cara Insertion dan Deletion.
1. Push Head : berarti menambahkan data dari depan.
Misalkan kita mempunyai sebuah struct :
Berikut adalah contoh code Push Tail dalam single linked list:
Berikut adalah contoh code Pop Head dalam single linked list:
Berikut adalah contoh code Pop dalam single linked list:
Dalam Linked List terdapat berbagai macam cara Insertion dan Deletion.
1. Push Head : berarti menambahkan data dari depan.
Misalkan kita mempunyai sebuah struct :
Berikut merupakan contoh code untuk Push Tail pada double linked list:
Berikut merupakan contoh code Push Mid pada double linked list:
Berikut merupakan contoh code Pop Head dalam double linked list:
Berikut merupakan contoh code Pop Tail dalam double linked list:
Berikut merupakan contoh code Pop dalam double linked list:
1. Push Head : berarti menambahkan data dari depan.
Misalkan kita mempunyai sebuah struct :
Berikut adalah contoh code Push Head dalam single linked list:struct data{int angka;struct data*next;}*head,*tail,*curr;
2. Push Tail : berarti menambahkan data dari belakang.void pushHead(int angka){curr = (struct data*) malloc (sizeof (struct data));curr->angka = angka;if(head == NULL){head = tail = curr;tail->next = NULL;}else{curr->next = head;head = curr;}}
Berikut adalah contoh code Push Tail dalam single linked list:
3. Pop Head : berarti menghilangkan data yang berada di depan.void pushTail(int angka){curr = (struct data*) malloc (sizeof (struct data));curr->angka = angka;if(head == NULL){head = tail = curr;tail->next = NULL;}else{tail->next = curr;tail = curr;tail->next = NULL;}}
Berikut adalah contoh code Pop Head dalam single linked list:
void popHead(){
if(head!=NULL){
curr = head;
head = head->next;
free(curr);
}
}4. Pop : berarti menghilangkan data yang kita inginkan.
Berikut adalah contoh code Pop dalam single linked list:
void pop(int angka){
curr = head;
if(curr->angka == angka) popHead();
else{
while(curr->next->angka != angka){
curr = curr->next;
}
struct data*temp;
temp = curr->next;
curr->next = temp->next;
free(temp);
}
}
Double Linked List
Dalam Double Linked List yang harus kita ingat konsepnya adalah "Head - Tail" dengan Head yang sebelumnya menuju ke NULL dan Tail yang juga setelahnya menuju ke NULL.Dalam Linked List terdapat berbagai macam cara Insertion dan Deletion.
1. Push Head : berarti menambahkan data dari depan.
Misalkan kita mempunyai sebuah struct :
Berikut merupakan contoh code untuk Push Head dalam double linked list:struct data{int angka;struct data*next, *prev;}*head, *tail, *curr;
void pushHead(int angka){
curr = (struct data*) malloc (sizeof(struct data));
curr->angka = angka;
if(head==NULL) head = tail = curr;
else{
curr->next = head;
head->prev = curr;
head = curr;
}
tail->next = head->prev = NULL;
}2. Push Tail : berarti menambahkan data dari belakang.
Berikut merupakan contoh code untuk Push Tail pada double linked list:
void pushTail(int angka){
curr = (struct data*) malloc (sizeof(struct data));
curr->angka = angka;
if(head==NULL) head = tail = curr;
else {
tail->next = curr;
curr->prev = tail;
tail = curr;
}
tail->next = head->prev = NULL;
}3. Push Mid : berarti menyisipkan data dari tengah (digunakan untuk mengurutkan data).
Berikut merupakan contoh code Push Mid pada double linked list:
void push(int angka){
curr = (struct data*) malloc (sizeof(struct data));
curr->angka = angka;
if(head==NULL) head = tail = curr;
else if(curr->angka < head->angka) pushHead(angka);
else if(curr->angka > tail->angka) pushTail(angka);
else{
struct data*temp;
temp = head;
while (temp->next->angka < curr->angka) temp = temp->next;
curr->next = temp->next;
temp->next->prev = curr;
temp->next = curr;
curr->prev = temp;
}
}4. Pop Head : berarti menghapus data yang berada di depan.
Berikut merupakan contoh code Pop Head dalam double linked list:
5. Pop Tail : berarti menghapus data yang berada di belakang.void popHead(){curr = head;head = head->next;free(curr);head->prev = NULL;}
Berikut merupakan contoh code Pop Tail dalam double linked list:
void popTail(){
curr = tail;
tail = tail->prev;
free(curr);
tail->next = NULL;
}6. Pop : berarti menghilangkan data yang kita inginkan.
Berikut merupakan contoh code Pop dalam double linked list:
void pop(int angka){
if(head->angka == angka) popHead();
else if(tail->angka == angka) popTail();
else{
struct data*temp = head;
while(temp->next->angka!=angka) temp = temp->next;
curr = temp->next;
temp->next = curr->next;
curr->next->prev = temp;
free(curr);
}
}
Hashing Table & Binary Tree
Hashing
Hashing adalah proses memetakan sejumlah besar item data ke tabel yang lebih kecil dengan bantuan fungsi hashing. Ini adalah teknik untuk mengubah rentang nilai kunci menjadi rentang indeks array.
Ini digunakan untuk memfasilitasi metode pencarian tingkat selanjutnya jika dibandingkan dengan pencarian linear atau biner. Hashing memungkinkan untuk memperbarui dan mengambil entri data apa pun dalam waktu konstan O (1). Waktu konstan O (1) berarti operasi tidak tergantung pada ukuran data. Hashing digunakan dengan database untuk memungkinkan item diambil lebih cepat.
Ini digunakan dalam enkripsi dan dekripsi tanda tangan digital.
Hash Function
Proses tetap yang mengubah kunci ke kunci hash dikenal sebagai Fungsi Hash. Fungsi ini mengambil kunci dan memetakannya ke nilai dengan panjang tertentu yang disebut nilai Hash atau Hash. Nilai hash mewakili string karakter asli, tetapi biasanya lebih kecil dari aslinya. Ini mentransfer tanda tangan digital dan kemudian nilai hash dan tanda tangan dikirim ke penerima. Penerima menggunakan fungsi hash yang sama untuk menghasilkan nilai hash dan kemudian membandingkannya dengan yang diterima dengan pesan. Jika nilai hash sama, pesan dikirim tanpa kesalahan.
Hash Table
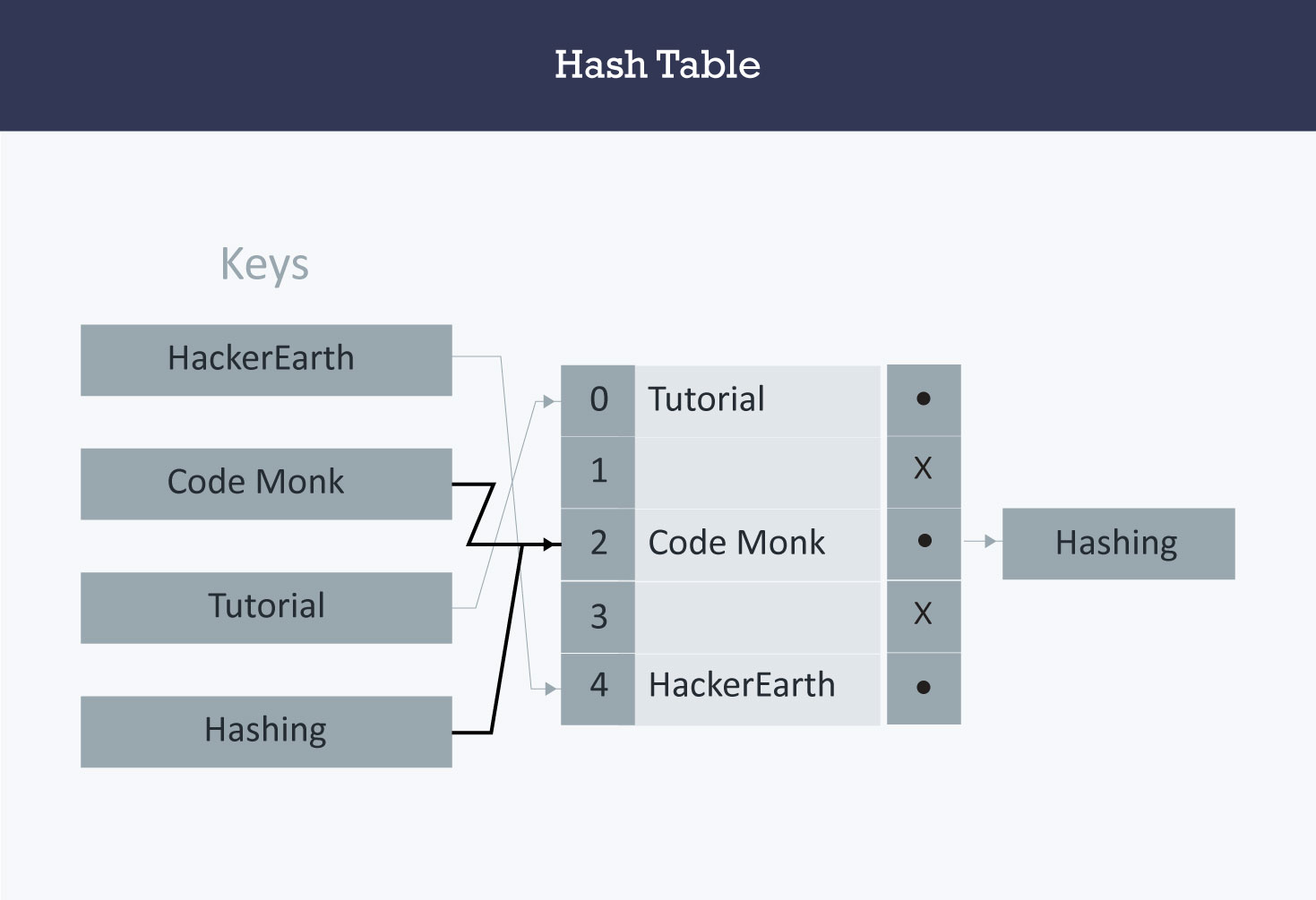
Hash Table adalah jenis struktur data yang digunakan untuk menyimpan dan mengakses data dengan sangat cepat. Penyisipan data dalam tabel didasarkan pada nilai kunci. Karenanya setiap entri dalam tabel hash didefinisikan dengan beberapa kunci. Dengan menggunakan data kunci ini dapat dicari dalam tabel hash dengan beberapa perbandingan kunci dan kemudian waktu pencarian tergantung pada ukuran hash table.
Contoh implementasi dalam C :
#include <stdio.h> #include <string.h> #include <stdlib.h> #include <stdbool.h> #define SIZE 20 struct DataItem { int data; int key; }; struct DataItem* hashArray[SIZE]; struct DataItem* dummyItem; struct DataItem* item; int hashCode(int key) { return key % SIZE; } struct DataItem *search(int key) { //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray[hashIndex] != NULL) { if(hashArray[hashIndex]->key == key) return hashArray[hashIndex]; //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; } void insert(int key,int data) { struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem)); item->data = data; item->key = key; //get the hash int hashIndex = hashCode(key); //move in array until an empty or deleted cell while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) { //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } hashArray[hashIndex] = item; } struct DataItem* delete(struct DataItem* item) { int key = item->key; //get the hash int hashIndex = hashCode(key); //move in array until an empty while(hashArray[hashIndex] != NULL) { if(hashArray[hashIndex]->key == key) { struct DataItem* temp = hashArray[hashIndex]; //assign a dummy item at deleted position hashArray[hashIndex] = dummyItem; return temp; } //go to next cell ++hashIndex; //wrap around the table hashIndex %= SIZE; } return NULL; } void display() { int i = 0; for(i = 0; i<SIZE; i++) { if(hashArray[i] != NULL) printf(" (%d,%d)",hashArray[i]->key,hashArray[i]->data); else printf(" ~~ "); } printf("\n"); } int main() { dummyItem = (struct DataItem*) malloc(sizeof(struct DataItem)); dummyItem->data = -1; dummyItem->key = -1; insert(1, 20); insert(2, 70); insert(42, 80); insert(4, 25); insert(12, 44); insert(14, 32); insert(17, 11); insert(13, 78); insert(37, 97); display(); item = search(37); if(item != NULL) { printf("Element found: %d\n", item->data); } else { printf("Element not found\n"); } delete(item); item = search(37); if(item != NULL) { printf("Element found: %d\n", item->data); } else { printf("Element not found\n"); } }
Hash table menggunakan fungsi hash untuk menghitung indeks ke dalam array dari ember atau slot, dari mana nilai yang diinginkan dapat ditemukan. tetapi block chain adalah buku besar digital di mana transaksi yang dilakukan dalam bitcoin atau mata uang digital lain dicatat secara kronologis dan terbuka.
Binary Tree
Binary Tree adalah struktur data hierarkis di mana setiap simpul memiliki paling banyak dua anak yang umumnya disebut anak kiri dan anak kanan.
Setiap node berisi tiga komponen:
- Pointer ke subtree kiri
- Pointer ke subtree kanan
- Elemen data
Node paling atas di pohon disebut root. Pohon kosong diwakili oleh pointer NULL.
 |
| Jenis - Jenis Binary Tree |
Binary Search Tree
Pendahuluan
Binary Search Tree (BST) adalah sebuah binary tree yang memiliki ciri-ciri sebagai berikut :
1. Setiap node mempunyai value dan tidak ada value yang double
2. Value yang ada di kiri tree lebih kecil dari rootnya
3. Value yang ada di kanan tree lebih besar dari rootnya
4. Kiri dan kanan tree bisa menjadi root lagi atau bisa mempunya child jadi BST ini memiliki sifat ( rekrusif )
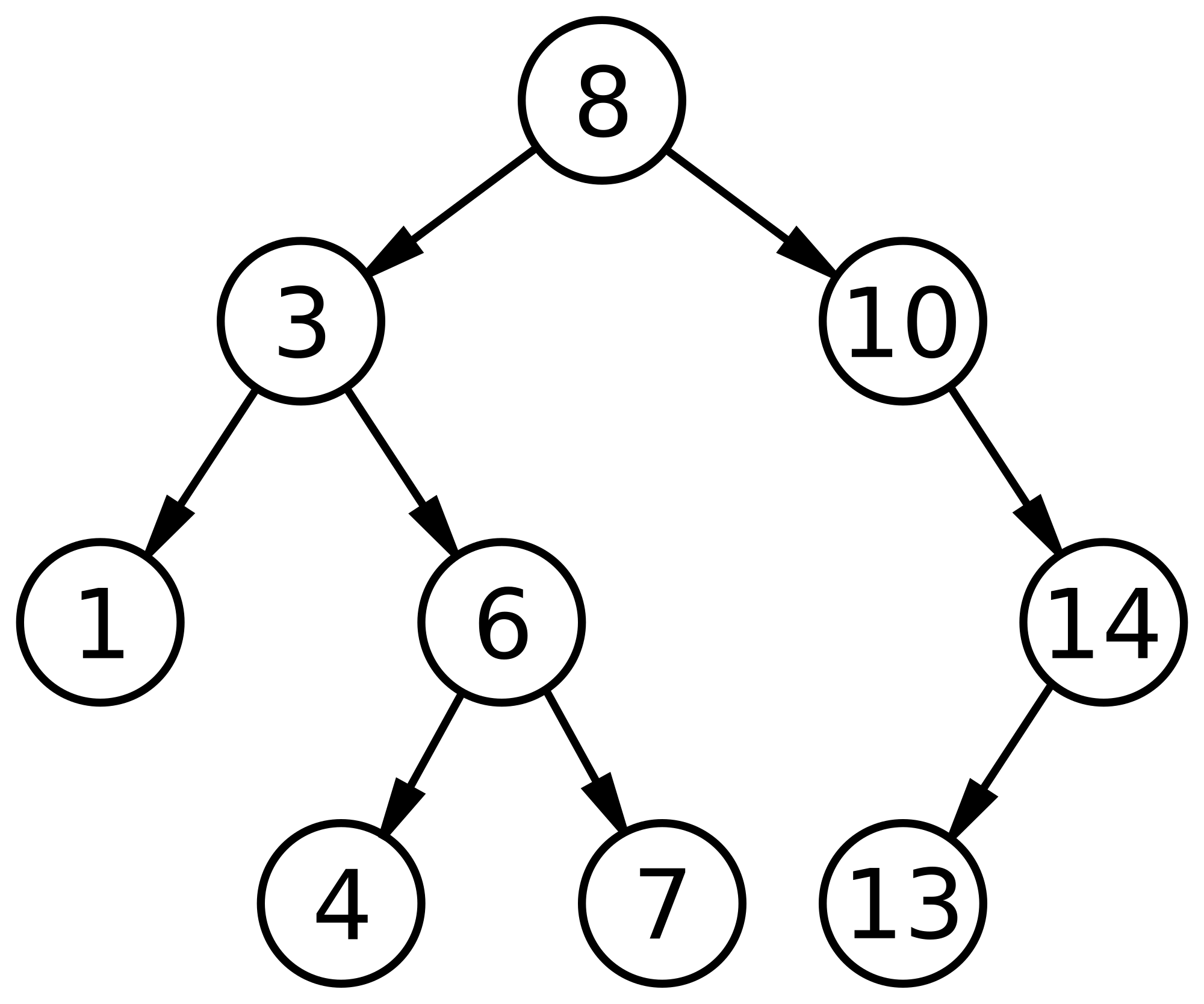
Operasi Dasar
Binary Search Tree memiliki 3 operasi dasar yaitu :
1. Searching : mencari value di dalam BST
1. Searching : mencari value di dalam BST
2. Insertion : memasukkan value baru ke dalam BST
3. Deletion : menghapus key / value dari BST
Searching
Bayangkan kita akan mencari value X :
1. Memulai Pencarian Dari Root
2. Jika Root adalah value yang kita cari , maka berhenti
3. Jika x lebih kecil dari root maka cari kedalam rekursif tree sebelah kiri
4. Jika x lebih besar dari root maka cari kedalam rekursif tree sebelah kanan
Insertion
Bayangkan kita menginsert value x :
1. Dimulai dari root
2. Jika x lebih kecil dari node value(key) kemudian cek dengan sub-tree sebelah kiri lakukan pengecekan secara berulang ( rekursif )
3. Jika x lebih besar dari node value(key) kemudian cek dengan sub-tree sebelah kanan lakukan pengecekan secara berulang ( rekursif )
4. Ulangi sampai menemukan node yang kosong untuk memasukan value X ( X akan selalu berada di paling bawah biasa di sebut Leaf atau daun )
Deletion
Akan ada 3 case yang ditemukan ketika ingin menghapus yang perlu diperhatikan :
1. Jika value yang ingin dihapus adalah Leaf(Daun) atau paling bawah , langsung delete
2. Jika value yang akan dihapus mempunyai satu anak, hapus nodenya dan gabungkan anaknya ke parent value yang dihapus
3. Jika value yang akan di hapus adalah node yang memiliki 2 anak , maka ada 2 cara , kita bisa cari dari left sub-tree anak kanan paling terakhir(leaf) (kiri,kanan)
Tugas Dreamers Market :
https://drive.google.com/open?id=1cUo6YjAkJEE4C8byuZoAJd3MvgEsQCc4
https://drive.google.com/open?id=1cUo6YjAkJEE4C8byuZoAJd3MvgEsQCc4

Comments
Post a Comment